


If you increase the number of transistors, you can have more words. With 8 bits, you can represent a number between 0 and 255. With 16 bits you can represent a number between 0 and 65536. With 32 bits you can represent a number between 0 and 4,294,967,296.
To represent a language, we need to design a data interchange code for the letters, numbers and symbols in that language. The first coding standard was ASCII, the American Standard Code for Information Interchange, which encoded the English alphabet. In ASCII each alphanumeric character or symbol is given a number. 'A' is 65, 'B' is 66, 'a' is 97, 'b' is 98. The first ASCII version encoded the English language with numbers between 32 and 127.
Using ASCII, the word "Assyria" would be stored internally in a computer as follows:
Character A s s y r i a
ASCII code 65 115 115 121 114 105 97
The computer does not know that 65 is "A". It is the software that determines how to interpret the numbers stored in a computer. In a text editor 65 would be "A", in a calculator 65 could mean the number 65.
Other data interchange codes were developed, notably IBM's Extended, Binary Coded Data Interchange Code, which is used on mainframes. Extended ASCII was developed, which supported some of the other languages based on the Latin script.
But for most languages there was no standard, and software which attempted to support these languages used proprietary coding schemes. Documents produced by one software application could not be used by another software application. Whereas documents written in ASCII could be read by any text processing software on any computer.
This was the state of the industry until 1987, when engineers at Xerox and Apple began informal discussions on a new data interchange code, Unicode, to represent all languages of the world. Four years later the Unicode Consortium was incorporated, in January, 1991, and the first version of Unicode was published in October, 1991. Version 2 was published in July, 1996. Version 3, which contained the Assyrian standard, was published in September, 1999.
Adoption of the Unicode standard by software companies, notably Microsoft and Apple, allowed files written on one computer system or software product to be used by any other computer system or software product.
Unicode is now universally used by all operating systems (Windows, Apple, Linux, Android) and all hardware devices (computers, tablets, phones, refrigerators, stoves), making it possible to send Assyrian text across disparate operating systems and devices, and across the world.
Early Attempts at Computer Support for Assyrian
The earliest documented support for Assyrian computer processing was by Peter BetBasoo in 1983, when he programmed his Timex Sinclair 2068 computer to write and print in Assyrian. This was a technologically limited implementation, supporting only the alphabet, with no support for diacritical marks and other symbols. The coding scheme for the Assyrian alphabet was proprietary.

After the development of TrueType font technology by Apple in the mid-1980s, several word processers were developed on the Mac and PC platforms for Assyrian, but they all used proprietary coding schemes and their files were incompatible with each other.
A fairly successful implementation was developed for the IBM PC by Sargon Hasso and Eshoo Marcus. This again used a proprietary coding scheme.
In May, 1989 the First Ashurbanipal Library Computer Conference was held in Chicago. This Conference was organized by Peter BetBasoo and attended by Sargon Hasso, George Kiraz and others. The conference produced a coding standard for Assyrian called Extended Syriac Codes for Information Interchange (ESCII) and a standard Assyrian keyboard layout based on a frequency of use analysis of each Assyrian letter.
Some of this work was used in creating the Syriac Unicode Standard.
Unicode Learns Assyrian
In mid-1992 Sargon Hasso and Peter BetBasoo independently contacted the Unicode Consortium and began dialog on how to add the Assyrian language to the Unicode standard. The Unicode representative, Rick McGowan of NeXT, Inc., informed Peter and Sargon of each other's work, after which they worked together on producing the first draft of the Assyrian Unicode standard, which had the proposed name of "Syriac Unicode Standard."
A language encoding must be able to represent text and writing in that language, and must, therefore, contain all the letters and symbols used by that language, as well as sorting and collating rules, typographical rules and other standard characteristics of the language.
There was special consideration for Assyrian, given its 2000-year history. The Assyrian standard had to be able to represent documents written at any time in the previous 2000 years. Another consideration was supporting the Mandaic language, which uses the same alphabet.
Peter and Sargon conducted extensive research on the Assyrian language and produced a draft Unicode proposal for Assyrian that supported Assyrian documents from 33 A.D. to the present, and also supported Mandaic.
The Unicode standard encodes semantics, not typographical details. In other words, the same letter, say "A", can be shown in different fonts, but its code remains the same. For the three scripts of Assyrian, Eastern, Estrangelo and Western (serto), the same encoding scheme is used. There are also some codes which are shared with Arabic and Hebrew and other languages, and the same definition is used by all three languages. The "uni" in Unicode stands for "unified." By eliminating the duplicates between the world's languages, Unicode is able to encode nearly all of them using 65536 code points.
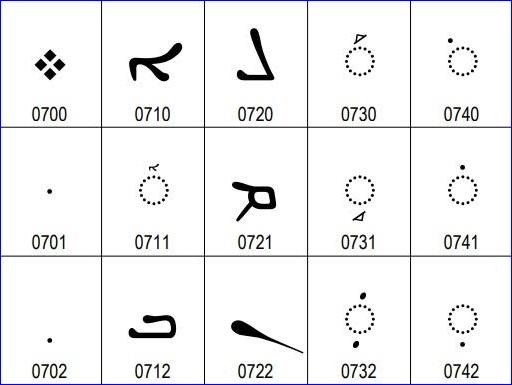
The rules of how Assyrian is written were defined in the Unicode standard. In Assyrian, the shape of the letter changes based on its location in a word (isolated, initial, middle, end), as well as how it connects to the letters preceding and following it.
In Assyrian, vowels (called paroshe) are represented by diacritical marks. Three sets of diacritical marks have been used by Assyrian in the past 2000 years. These were combined into one set in the Assyrian Unicode standard.
The first draft proposal for the Assyrian Unicode standard was submitted to Rick McGowan and the Unicode Consortium on October 11, 1993.
This draft was also presented by Peter BetBasoo at the First International Forum on Syriac Computing in 1995 at the Catholic University of America, and published in the proceedings of that conference.
A second draft of the proposal, containing minor updates, was presented in 1997.
A third draft was presented by Sargon Hasso, George Kiraz and Paul Nelson on February 27, 1998. This draft had minor updates to the second proposal. It removed support for Mandaic. This third draft would be the version officially adopted by the Unicode Consortium.
It took six years for the Assyrian proposal to be approved and it was officially included in the Unicode 3.0 version, published in September, 1999. Support for Unicode 3.0 by software companies quickly followed. By the early 2000s Assyrian was officially supported by all platforms that supported Unicode 3.0.
Cultural, Religious and Political Considerations
There were many Assyrian issues discussed with Rick McGowan and the Unicode Consortium, and recommendations made. Some made their way into the standard, others did not.
The issue of naming the three Assyrian scripts was discussed, and Sargon Hasso advised Rick McGowan to avoid the names "Nestorian," "Jacobite" and "Chaldean." The names Eastern, Western (serto) and Estrangelo were officially adopted instead.
Peter BetBasoo lobbied Rick McGowan to use the name "Assyrian Unicode Standard" instead of "Syriac Unicode Standard" but this was not successful.
Conclusion
The Syriac Unicode Standard brought the Assyrian language into the modern age of computing, allowing it to exist and thrive in the virtual world of computing and in the real world. The standard allowed the Assyrian language to use the power of computers for document generation, typesetting, printing, word processing, spell checking, optical character recognition, email, instant messaging and anything else that is possible to do today on computers and on the internet.
Documents
- 1993-02-03: Letter from Peter BetBasoo to Rick McGowan
- 1993-07-08: Letter from Sargon Hasso to Peter BetBasoo
- 1993-10-11: Letter from Sargon Hasso to Rick McGowan
- 1993-10-22: Letter from Rick McGowan to Peter BetBasoo
- 1993-11-09: Letter from Sargon Hasso to Peter BetBasoo
- 1995-01-05: Letter from Peter BetBasoo to George Kiraz
- Peter BetBasoo handwritten notes
- Various related material
- Recommendations of the First Ashurbanipal Library Computer Conference
- Proposed Syriac Computer Keyboard Layout, by George Kiraz
- A Dynamic Storage Model For Assyrian Computer Text, by Peter BetBasoo
- Syriac Unicode Standard, article by Peter BetBasoo, 1995
- Official Syriac Unicode Standard, latest version
or register to post a comment.